
三年面试经验分享:前端面试的四个阶段和三个决定因素
今年的就业形式简直一片黑暗,本着明年会比今年还差的“侥幸心理”,我还是毫不犹豫地选择裸辞了,历经一个半月的努力,收到了还算不错的 offer,薪资和平台都有比较大的提升,但还是和自己的心理预期有着很大的差距。所以得出最大的结论就是:不要裸辞!不要裸辞!不要裸辞!因为面试期间带给人的压力,和现实与理想的落差对心理的摧残是不可估量的,在这样一个环境苟着是不错的选择。
接下来总结一般情况下前端面试中会经历的以下四个阶段和三个决定因素:
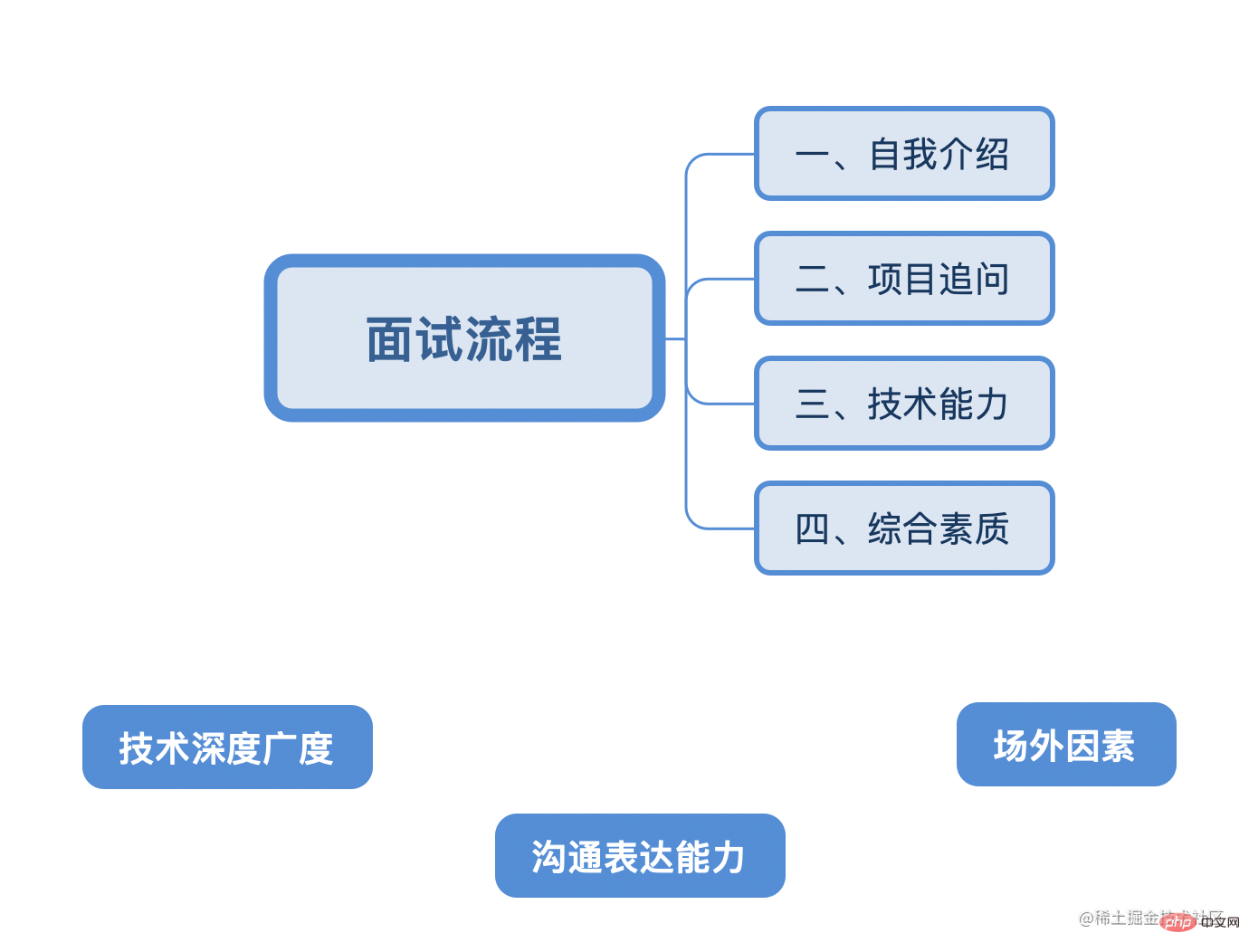 作为前端人员,技术的深度广度是排在第一位的,三年是一个分割线,一定要在这个时候找准自己的定位和方向。
作为前端人员,技术的深度广度是排在第一位的,三年是一个分割线,一定要在这个时候找准自己的定位和方向。
其次良好的沟通表达能力、着装和表现等场外因素能提高面试官对你的认可度。
有的人技术很牛逼,但是面试时让面试官觉得不爽,觉得你盛气逼人/形象邋遢/自以为是/表述不清,就直接不要你,那是最得不偿失的。
一、自我介绍
面试官让你自我介绍,而且不限定自我介绍的范围,肯定是面试官想从你的自我介绍中了解到你,所以介绍一定要保证简短和流畅,面对不同的面试官,自我介绍的内容可以是完全一样的,所以提前准备好说辞很重要,并且一定要注意:不要磕磕巴巴,要自信!流畅的表达和沟通能力,同样是面试官会对候选人考核点之一。我也曾当过面试官,自信大方的候选人,往往更容易受到青睐。
1、个人介绍(基本情况),主要的简历都有了,这方面一定要短
2、个人擅长什么,包括技术上的和非技术上的。技术上可以了解你的转场,非技术可以了解你这个人
3、做过的项目,捡最核心的项目说,不要把所有项目像背书一样介绍
4、自己的一些想法、兴趣或者是观点,甚至包括自己的职业规划。这要是给面试官一个感觉:热衷于"折腾"或者"思考"
示例:
面试官您好,我叫xxx,xx年毕业于xx大学,自毕业以来一直从事着前端开发的相关工作。
我擅长的技术栈是 vue 全家桶,对 vue2 和 vue3 在使用上和源码都有一定程度的钻研;打包工具对 webpack 和 vite 都比较熟悉;有从零到一主导中大型项目落地的经验和能力。
在上家公司主要是xx产品线负责人的角色,主要职责是。。。。。。
除了开发相关工作,还有一定的技术管理经验:比如担任需求评审、UI/UE交互评审评委,负责开发排期、成员协作、对成员代码进行review、组织例会等等
平常会在自己搭建的博客上记录一些学习文章或者学习笔记,也会写一些原创的技术文章发表到掘金上,获得过xx奖。
总的来说自我介绍尽量控制在3 - 5分钟之间,简明扼要为第一要义,其次是突出自己的能力和长处。
对于普通的技术面试官来说,自我介绍只是习惯性的面试前的开场白,一般简历上列举的基本信息已经满足他们对你的基本了解了。但是对于主管级别的面试官或者Hr,会看重你的性格、行为习惯、抗压能力等等综合能力。所以要让自己在面试过程尽可能表现的积极向上,爱好广泛、喜欢持续学习,喜欢团队合作,可以无条件加班等等。当然也不是说让你去欺骗,只是在现在这种环境中,这些“侧面能力”也是能在一定程度提升自己竞争力的法宝。
二、项目挖掘
在目前这个行情,当你收到面试通知时,有很大概率是因为你的项目经验和所招聘的岗位比较符合。 所以在项目的准备上要额外上心,比如:
对项目中使用到的技术的深挖
对项目整体设计思路的把控
对项目运作流程的管理
团队协作的能力。
项目的优化点有哪些
这些因人而异就不做赘述了,根据自己的情况好好挖掘即可。
三、个人
先说个人,当你通过了技术面试,到了主管和hr这一步,不管你当前的技术多牛逼,他们会额外考察你个人的潜力、学习能力、性格与团队的磨合等软实力,这里列出一些很容易被问到的:
为什么跳槽?
直接从个人发展入手表现出自己的上进心:
一直想去更大的平台,不但有更好的技术氛围,而且学到的东西也更多
- 想扩展一下自己的知识面,之前一致是做x端的 xx 产品,技术栈比较单一一点,相对xx进行学习。
- 之前的工作陷入了舒适圈,做来做去也就那些东西,想要换个平台扩宽自己的技术广度,接触和学习一些新的技术体系,为后续的个人发展更有利
讲讲你和普通前端,你的亮点有哪些?
1、善于规划和总结,我会对自己经手的项目进行一个全面的分析,一个是业务拆解,对个各模块的业务通过脑图进行拆解;另一个就是对代码模块的拆解,按功能去区分各个代码模块。再去进行开发。我觉得这是很多只会进行盲目业务开发的前端做不到的
2、喜欢专研技术,平常对 vue 的源码一直在学习,也有输出自己的技术文章,像之前写过一篇逐行精读 teleport 的源码,花了大约有三十个小时才写出来的,对每一行源码的功能和作用进行了解读(但是为啥阅读和点赞这么低)。
你有什么缺点?
性子比较沉,更偏内向一点,所以我也会尝试让自己变得外向一点。
一个是要开各种评审会,作为前端代表需要我去准备各种材料和进行发言。
所以在团队内做比较多的技术分享,每周主持例会,也让我敢于去表达和探讨。
最近有关注什么新技术吗?
包依赖管理工具 pnpm(不会重复安装依赖,非扁平的node_modules结构,符号链接方式添加依赖包)
打包工具 vite (极速的开发环境)
flutter (Google推出并开源的移动应用程序(App)开发框架,主打跨平台、高保真、高性能)
rust(听说是js未来的基座)
turbopack,webpack的继任者,说是比 vite快10倍,webpack快700倍,然后尤雨溪亲自验证其实并没有比 vite 快10倍
webcomponents
你是偏向于走各个方向探索还是一直向某个方向研究下去?
我对个人的规划是这样的:
3 - 5 年在提高自己的技术深度的同时,扩宽自己的知识面,就是深度和广度上都要有提升,主要是在广度上,充分对大前端有了认知才能更好的做出选择
5 - 7 年就是当有足够的知识积累之后再选择某一个感兴趣方向深研下去,争取成为那个领域的专家
团队规模,团队规范和开发流程
这个因人而异,如实准备即可,因为不同规模团队的研发模式差别是很大的。
代码 review 的目标
1、最注重的是代码的可维护性(变量命名、注释、函数单一性原则等)
2、扩展性:封装能力(组件、代码逻辑是否可复用、可扩展性)
3、ES 新特性(es6+ 、ES2020, ES2021 可选链、at)
4、函数使用规范(比如遇到用 map 拿来当 forEach 用的)
5、性能提升,怎样运用算法,写出更加优雅,性能更好的代码
如何带领团队的
我在上家公司是一个技术管理的角色。
0、落实开发规范,我在公司内部 wiki 上有发过,从命名、最佳实践到各种工具库的使用。新人进来前期我会优先跟进他们的代码质量
1、团队分工:每个人单独负责一个产品的开发,然后公共模块一般我会指定某几个人开发
2、代码质量保证:每周会review他们的代码,也会组织交叉 review 代码,将修改结果输出文章放到 wiki中
3、组织例会:每周组织例会同步各自进度和风险,根据各自的进度调配工作任务
4、技术分享:还会组织不定时的技术分享。一开始就是单纯的我做分享,比如微前端的体系,ice stark 的源码
5、公共需求池:比如webpack5/vite的升级;vue2.7的升级引入setup语法糖;pnpm的使用;拓扑图性能优化
6、优化专项:在第一版产品出来之后,我还发起过性能优化专项,首屏加载性能,打包体积优化;让每个人去负责对应的优化项
对加班怎么看?
我觉得加班一般会有两种情况:
一是项目进度比较紧,那当然以项目进度为先,毕竟大家都靠这个吃饭
二是自身能力问题,对业务不熟啊或者引入一个全新的技术栈,那么我觉得不仅要加班跟上,还要去利用空闲时间抓紧学习,弥补自己的不足
有什么兴趣爱好?
我平常喜欢阅读,就是在微信阅读里读一些心理学、时间管理、还有一些演讲技巧之类的书
然后是写文章,因为我发现单纯的记笔记很容易就忘了,因为只是记载别人的内容,而写自己的原创文章,在这个过程中能将知识非常高的比例转换成自身的东西,所以除了自个发掘金的文章,我也经常会对项目的产出有文章输出到 wiki 上
其他爱好就是和朋友约着打篮球、唱歌
四、技术
技术面试一定要注意:简明扼要,详略得当,不懂的就说不懂。因为在面试过程中是一个和面试官面对面交流的过程,没有面试官会喜欢一个絮絮叨叨半天说不到重点候选人,同时在说话过程中,听者会被动的忽略自己不感兴趣的部分,所以要着重突出某个技术的核心特点,并围绕着核心适当展开。
大厂基本都会通过算法题来筛选候选人,算法没有捷径,只能一步一步地刷题再刷题,这方面薄弱的要提前规划进行个学习了。
技术面过程主要会对前端领域相关的技术进行提问,一般面试官会基于你的建立,而更多的是,面试官基于他之前准备好的面试题,或者所在项目组比较熟悉的技术点进行提问,因为都是未知数,所以方方面面都还是要求比较足的。
如果想进入一个中大型且发展前景不错的公司,并不是照着别人的面经背一背就能糊弄过去的,这里作出的总结虽然每一条都很简短,但都是我对每一个知识点进行全面学习后才提炼出来的部分核心知识点,所以不惧怕面试官的“发散一下思维”。
面试过程一般会涉及到以下八大知识类型的考量:
JS/CSS/TypeScript/框架(Vue、React)/浏览器与网络/性能优化/前端工程化/架构/其他
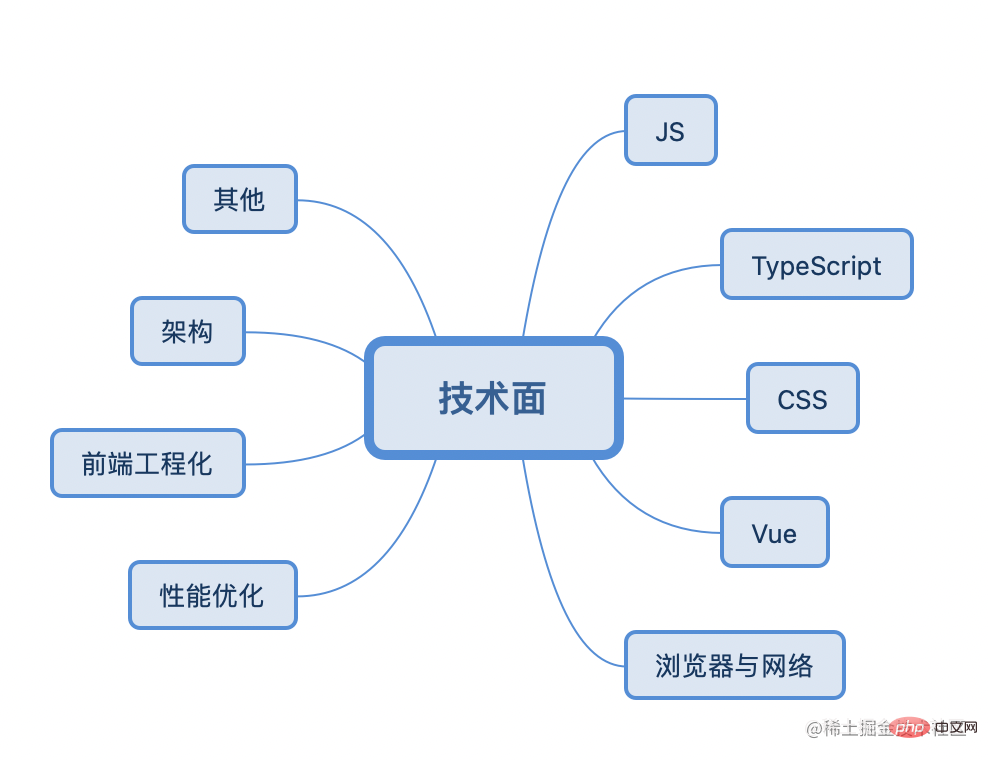
所以面试前的技术准备绝不是一蹴而就,还需要平时的积累,比如可以利用每天十到二十分钟对其中一个小知识点进行全面的学习,长此以往,无论是几年的面试,都足够侃侃而谈。
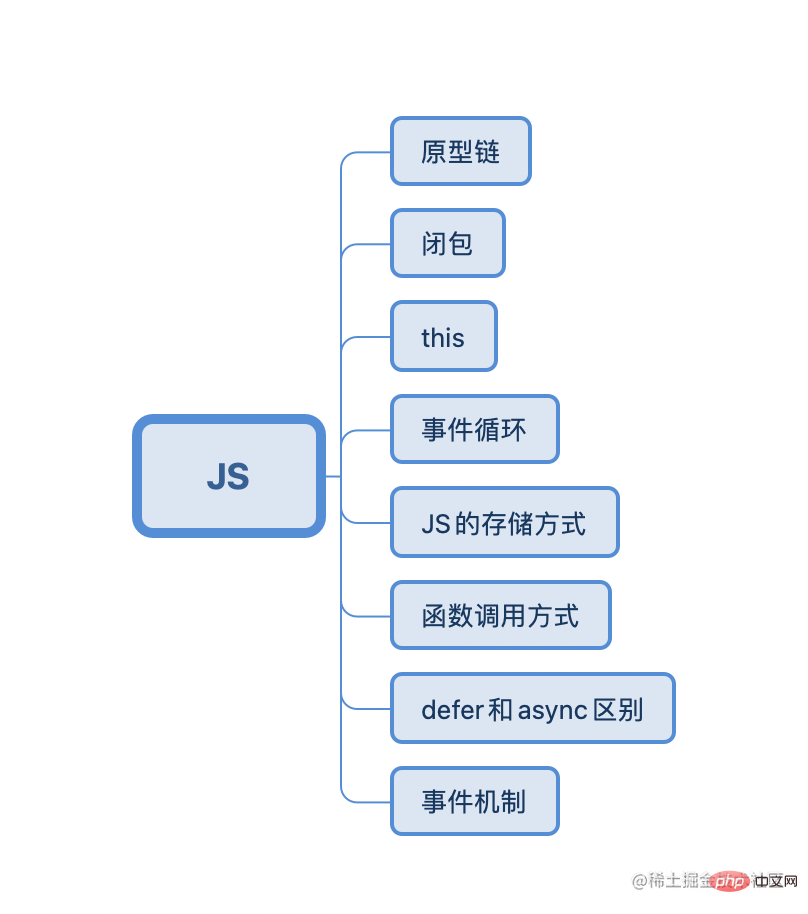
JS篇
JS的学习梭哈红包书和冴羽老师的深入JS系列博客就基本ok了
常见的JS面试题一般会有这些
什么是原型/原型链?
原型的本质就是一个对象。
当我们在创建一个构造函数之后,这个函数会默认带上一个prototype属性,而这个属性的值就指向这个函数的原型对象。
这个原型对象是用来为通过该构造函数创建的实例对象提供共享属性,即用来实现基于原型的继承和属性的共享
所以我们通过构造函数创建的实例对象都会从这个函数的原型对象上继承上面具有的属性
当读取实例的属性时,如果找不到,就会查找与对象关联的原型中的属性,如果还查不到,就去找原型的原型,一直找到最顶层为止(最顶层就是Object.prototype的原型,值为null)。
所以通过原型一层层相互关联的链状结构就称为原型链。
什么是闭包?
定义:闭包是指引用了其他函数作用域中变量的函数,通常是在嵌套函数中实现的。
从技术角度上所有 js 函数都是闭包。
从实践角度来看,满足以下俩个条件的函数算闭包
即使创建它的上下文被销毁了,它依然存在。(比如从父函数中返回)
在代码中引用了自由变量(在函数中使用的既不是函数参数也不是函数局部变量的变量称作自由变量)
使用场景:
创建私有变量
vue 中的data,需要是一个闭包,保证每个data中数据唯一,避免多次引用该组件造成的data共享
延长变量的生命周期
一般函数的词法环境在函数返回后就被销毁,但是闭包会保存对创建时所在词法环境的引用,即便创建时所在的执行上下文被销毁,但创建时所在词法环境依然存在,以达到延长变量的生命周期的目的
应用
- 柯里化函数
- 例如计数器、延迟调用、回调函数等
this 的指向
在绝大多数情况下,函数的调用方式决定了 this 的值(运行时绑定)
1、全局的this非严格模式指向window对象,严格模式指向 undefined
2、对象的属性方法中的this 指向对象本身
3、apply、call、bind 可以变更 this 指向为第一个传参
4、箭头函数中的this指向它的父级作用域,它自身不存在 this
浏览器的事件循环?
js 代码执行过程中,会创建对应的执行上下文并压入执行上下文栈中。
如果遇到异步任务就会将任务挂起,交给其他线程去处理异步任务,当异步任务处理完后,会将回调结果加入事件队列中。
当执行栈中所有任务执行完毕后,就是主线程处于闲置状态时,才会从事件队列中取出排在首位的事件回调结果,并把这个回调加入执行栈中然后执行其中的代码,如此反复,这个过程就被称为事件循环。
事件队列分为了宏任务队列和微任务队列,在当前执行栈为空时,主线程回先查看微任务队列是否有事件存在,存在则依次执行微任务队列中的事件回调,直至微任务队列为空;不存在再去宏任务队列中处理。
常见的宏任务有setTimeout()、setInterval()、setImmediate()、I/O、用户交互操作,UI渲染
常见的微任务有promise.then()、promise.catch()、new MutationObserver、process.nextTick()
宏任务和微任务的本质区别
宏任务有明确的异步任务需要执行和回调,需要其他异步线程支持
微任务没有明确的异步任务需要执行,只有回调,不需要其他异步线程支持。
javascript中数据在栈和堆中的存储方式
1、基本数据类型大小固定且操作简单,所以放入栈中存储
2、引用数据类型大小不确定,所以将它们放入堆内存中,让它们在申请内存的时候自己确定大小
3、这样分开存储可以使内存占用最小。栈的效率高于堆
4、栈内存中变量在执行环境结束后会立即进行垃圾回收,而堆内存中需要变量的所有引用都结束才会被回收
讲讲v8垃圾回收
1、根据对象的存活时间将内存的垃圾回收进行不同的分代,然后对不同分代采用不同的回收算法
2、新生代采用空间换时间的 scavenge 算法:整个空间分为两块,变量仅存在其中一块,回收的时候将存活变量复制到另一块空间,不存活的回收掉,周而复始轮流操作
3、老生代使用标记清除和标记整理,标记清除:遍历所有对象标记标记可以访问到的对象(活着的),然后将不活的当做垃圾进行回收。回收完后避免内存的断层不连续,需要通过标记整理将活着的对象往内存一端进行移动,移动完成后再清理边界内存
函数调用的方法
1、普通function直接使用()调用并传参,如:function test(x, y) { return x + y},test(3, 4)
2、作为对象的一个属性方法调用,如:const obj = { test: function (val) { return val } }, obj.test(2)
3、使用call或apply调用,更改函数 this 指向,也就是更改函数的执行上下文
4、new可以间接调用构造函数生成对象实例
defer和async的区别
一般情况下,当执行到 script 标签时会进行下载 + 执行两步操作,这两步会阻塞 HTML 的解析;
async 和 defer 能将script的下载阶段变成异步执行(和 html解析同步进行);
async下载完成后会立即执行js,此时会阻塞HTML解析;
defer会等全部HTML解析完成且在DOMContentLoaded 事件之前执行。
浏览器事件机制
DOM 事件流三阶段:
捕获阶段:事件最开始由不太具体的节点最早接受事件, 而最具体的节点(触发节点)最后接受事件。为了让事件到达最终目标之前拦截事件。
比如点击一个div,则 click 事件会按这种顺序触发: document =>
<html>=><body>=><div>,即由 document 捕获后沿着 DOM 树依次向下传播,并在各节点上触发捕获事件,直到到达实际目标元素。目标阶段
当事件到达目标节点的,事件就进入了目标阶段。事件在目标节点上被触发(执行事件对应的函数),然后会逆向回流,直到传播至最外层的文档节点。
冒泡阶段
事件在目标元素上触发后,会继续随着 DOM 树一层层往上冒泡,直到到达最外层的根节点。
所有事件都要经历捕获阶段和目标阶段,但有些事件会跳过冒泡阶段,比如元素获得焦点 focus 和失去焦点 blur 不会冒泡
扩展一
e.target 和 e.currentTarget 区别?
e.target指向触发事件监听的对象。e.currentTarget指向添加监听事件的对象。
例如:
<ul>
<li><span>hello 1</span></li>
</ul>
let ul = document.querySelectorAll('ul')[0]
let aLi = document.querySelectorAll('li')
ul.addEventListener('click',function(e){
let oLi1 = e.target
let oLi2 = e.currentTarget
console.log(oLi1) // 被点击的li
console.log(oLi2) // ul
console.og(oLi1===oLi2) // false
})给 ul 绑定了事件,点击其中 li 的时候,target 就是被点击的 li, currentTarget 就是被绑定事件的 ul
事件冒泡阶段(上述例子),e.currenttarget和e.target是不相等的,但是在事件的目标阶段,e.currenttarget和e.target是相等的
作用:
e.target可以用来实现事件委托,该原理是通过事件冒泡(或者事件捕获)给父元素添加事件监听,e.target指向引发触发事件的元素
扩展二
addEventListener 参数
语法:
addEventListener(type, listener);
addEventListener(type, listener, options || useCapture);
type: 监听事件的类型,如:'click'/'scroll'/'focus'
listener: 必须是一个实现了 EventListener 接口的对象,或者是一个函数。当监听的事件类型被触发时,会执行
options:指定 listerner 有关的可选参数对象
- capture: 布尔值,表示 listener 是否在事件捕获阶段传播到 EventTarget 时触发
- once:布尔值,表示 listener 添加之后最多调用一次,为 true 则 listener 在执行一次后会移除
- passive: 布尔值,表示 listener 永远不会调用
preventDefault() - signal:可选,
AbortSignal,当它的abort()方法被调用时,监听器会被移除
useCapture:布尔值,默认为 false,listener 在事件冒泡阶段结束时执行,true 则表示在捕获阶段开始时执行。作用就是更改事件作用的时机,方便拦截/不被拦截。
Vue篇
笔主是主要从事 Vue相关开发的,也做过 react 相关的项目,当然 react 也只是能做项目的水平,所以在简历中属于一笔带过的那种,框架贵不在多而在精,对Vue源码系列的学习让我对Vue还是十分自信的。学习过程也是如此,如果你能够对一门框架达到精通原理的掌握程度,学习其他框架不过只是花时间的事情。
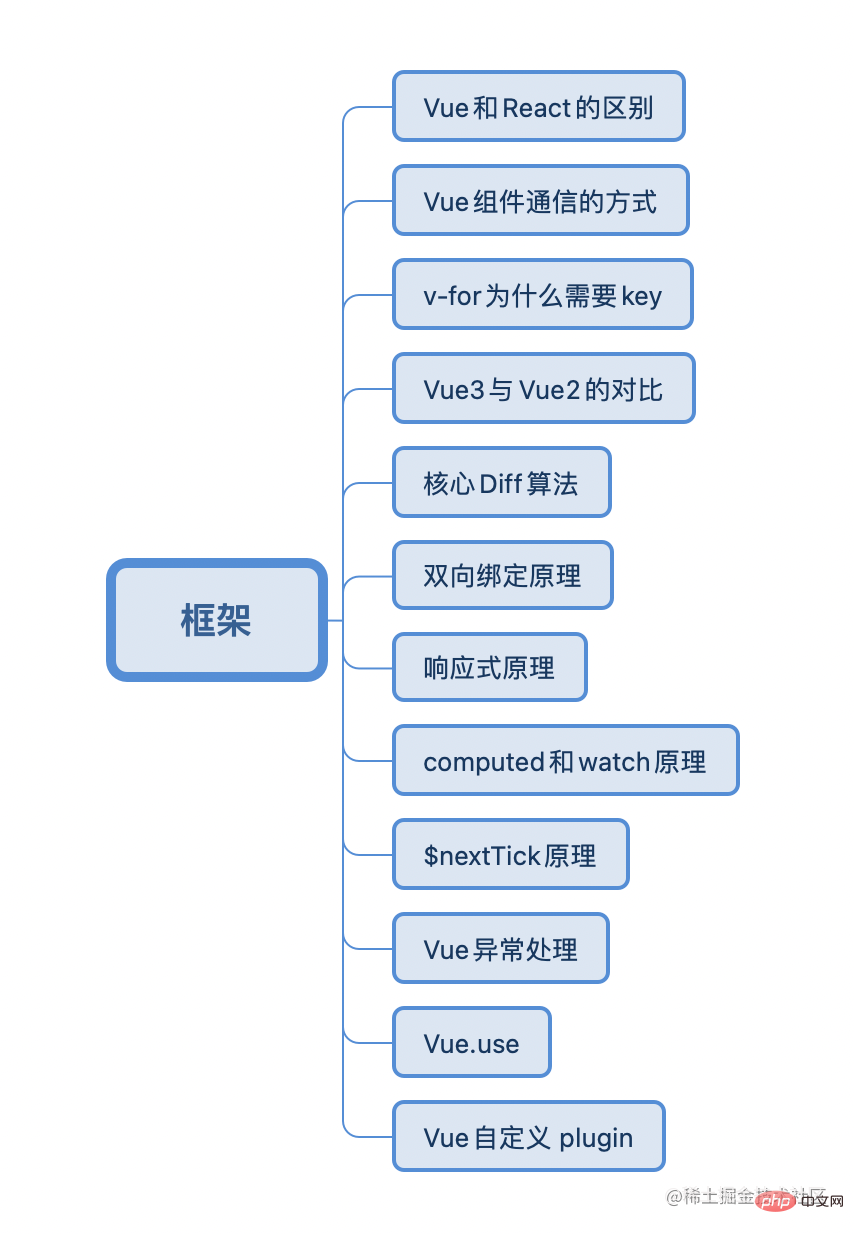
vue和react的区别
1、数据可变性
- React 推崇函数式编程,数据不可变以及单向数据流,只能通过
setState或者onchange来实现视图更新 - Vue 基于数据可变,设计了响应式数据,通过监听数据的变化自动更新视图
2、写法
- React 推荐使用 jsx + inline style的形式,就是 all in js
- Vue 是单文件组件(SFC)形式,在一个组件内分模块(tmplate/script/style),当然vue也支持jsx形式,可以在开发vue的ui组件库时使用
3、diff 算法
- Vue2采用双端比较,Vue3采用快速比较
react主要使用diff队列保存需要更新哪些DOM,得到patch树,再统一操作批量更新DOM。,需要使用shouldComponentUpdate()来手动优化react的渲染。
扩展:了解 react hooks吗
组件类的写法很重,层级一多很难维护。
函数组件是纯函数,不能包含状态,也不支持生命周期方法,因此无法取代类。
React Hooks 的设计目的,就是加强版函数组件,完全不使用"类",就能写出一个全功能的组件
React Hooks 的意思是,组件尽量写成纯函数,如果需要外部功能和副作用,就用钩子把外部代码"钩"进来。
vue组件通信方式
- props / $emit
- ref / $refs
- root
- attrs / listeners
- eventBus / vuex / pinia / localStorage / sessionStorage / Cookie / window
- provide / inject
vue 渲染列表为什么要加key?
Vue 在处理更新同类型 vnode 的一组子节点(比如v-for渲染的列表节点)的过程中,为了减少 DOM 频繁创建和销毁的性能开销:
对没有 key 的子节点数组更新是通过就地更新的策略。它会通过对比新旧子节点数组的长度,先以比较短的那部分长度为基准,将新子节点的那一部分直接 patch 上去。然后再判断,如果是新子节点数组的长度更长,就直接将新子节点数组剩余部分挂载;如果是新子节点数组更短,就把旧子节点多出来的那部分给卸载掉)。所以如果子节点是组件或者有状态的 DOM 元素,原有的状态会保留,就会出现渲染不正确的问题。
有 key 的子节点更新是调用的patchKeyedChildren,这个函数就是大家熟悉的实现核心 diff 算法的地方,大概流程就是同步头部节点、同步尾部节点、处理新增和删除的节点,最后用求解最长递增子序列的方法区处理未知子序列。是为了最大程度实现对已有节点的复用,减少 DOM 操作的性能开销,同时避免了就地更新带来的子节点状态错误的问题。
综上,如果是用 v-for 去遍历常量或者子节点是诸如纯文本这类没有”状态“的节点,是可以使用不加 key 的写法的。但是实际开发过程中更推荐统一加上 key,能够实现更广泛场景的同时,避免了可能发生的状态更新错误,我们一般可以使用 ESlint 配置 key 为 v-for 的必需元素。
想详细了解这个知识点的可以去看看我之前写的文章:v-for 到底为啥要加上 key?
vue3 相对 vue2的响应式优化
vue2使用的是Object.defineProperty去监听对象属性值的变化,但是它不能监听对象属性的新增和删除,所以需要使用$set、$delete这种语法糖去实现,这其实是一种设计上的不足。
所以 vue3 采用了proxy去实现响应式监听对象属性的增删查改。
其实从api的原生性能上proxy是比Object.defineProperty要差的。
而 vue 做的响应式性能优化主要是在将嵌套层级比较深的对象变成响应式的这一过程。
vue2的做法是在组件初始化的时候就递归执行Object.defineProperty把子对象变成响应式的;
而vue3是在访问到子对象属性的时候,才会去将它转换为响应式。这种延时定义子对象响应式会对性能有一定的提升
Vue 核心diff流程
前提:当同类型的 vnode 的子节点都是一组节点(数组类型)的时候,
步骤:会走核心 diff 流程
Vue3是快速选择算法
- 同步头部节点
- 同步尾部节点
- 新增新的节点
- 删除多余节点
- 处理未知子序列(贪心 + 二分处理最长递增子序列)
Vue2是双端比较算法
在新旧字节点的头尾节点,也就是四个节点之间进行对比,找到可复用的节点,不断向中间靠拢的过程
diff目的:diff 算法的目的就是为了尽可能地复用节点,减少 DOM 频繁创建和删除带来的性能开销
vue双向绑定原理
基于 MVVM 模型,viewModel(业务逻辑层)提供了数据变化后更新视图和视图变化后更新数据这样一个功能,就是传统意义上的双向绑定。
Vue2.x 实现双向绑定核心是通过三个模块:Observer监听器、Watcher订阅者和Compile编译器。
首先监听器会监听所有的响应式对象属性,编译器会将模板进行编译,找到里面动态绑定的响应式数据并初始化视图;watchr 会去收集这些依赖;当响应式数据发生变更时Observer就会通知 Watcher;watcher接收到监听器的信号就会执行更新函数去更新视图;
vue3的变更是数据劫持部分使用了porxy 替代 Object.defineProperty,收集的依赖使用组件的副作用渲染函数替代watcher
v-model 原理
vue2 v-model 原理剖析
V-model 是用来监听用户事件然后更新数据的语法糖。
其本质还是单向数据流,内部是通过绑定元素的 value 值向下传递数据,然后通过绑定 input 事件,向上接收并处理更新数据。
单向数据流:父组件传递给子组件的值子组件不能修改,只能通过emit事件让父组件自个改。
// 比如
<input v-model="sth" />
// 等价于
<input :value="sth" @input="sth = $event.target.value" />
给组件添加 v-model 属性时,默认会把value 作为组件的属性,把 input作为给组件绑定事件时的事件名:
// 父组件
<my-button v-model="number"></my-button>
// 子组件
<script>
export default {
props: {
value: Number, // 属性名必须是 value
},
methods: {
add() {
this.$emit('input', this.value + 1) // 事件名必须是 input
},
}
}
</script>如果想给绑定的 value 属性和 input 事件换个名称呢?可以这样:
在 Vue 2.2 及以上版本,你可以在定义组件时通过 model 选项的方式来定制 prop/event:
<script>
export default {
model: {
prop: 'num', // 自定义属性名
event: 'addNum' // 自定义事件名
}
}vue3 v-model 原理
实现和 vue2 基本一致
<Son v-model="modalValue"/>
等同于
<Son v-model="modalValue"/> <Son :modalValue="modalValue" @update:modalValue="modalUpdate=$event.target.value"/>
自定义 model 参数
<Son v-model:visible="visible"/>
setup(props, ctx){
ctx.emit("update:visible", false)
}vue 响应式原理
不管vue2 还是 vue3,响应式的核心就是观察者模式 + 劫持数据的变化,在访问的时候做依赖收集和在修改数据的时候执行收集的依赖并更新数据。具体点就是:
vue2 的话采用的是 Object.definePorperty劫持对象的 get 和 set 方法,每个组件实例都会在渲染时初始化一个 watcher 实例,它会将组件渲染过程中所接触的响应式变量记为依赖,并且保存了组件的更新方法 update。当依赖的 setter 触发时,会通知 watcher 触发组件的 update 方法,从而更新视图。
Vue3 使用的是 ES6 的 proxy,proxy 不仅能够追踪属性的获取和修改,还可以追踪对象的增删,这在 vue2中需要 delete 才能实现。然后就是收集的依赖是用组件的副作用渲染函数替代 watcher 实例。
性能方面,从原生 api 角度,proxy 这个方法的性能是不如 Object.property,但是 vue3 强就强在一个是上面提到的可以追踪对象的增删,第二个是对嵌套对象的处理上是访问到具体属性才会把那个对象属性给转换成响应式,而 vue2 是在初始化的时候就递归调用将整个对象和他的属性都变成响应式,这部分就差了。
扩展一
vue2 通过数组下标更改数组视图为什么不会更新?
尤大:性能不好
注意:vue3 是没问题的
why 性能不好?
我们看一下响应式处理:
export class Observer {
this.value = value
this.dep = new Dep()
this.vmCount = 0
def(value, '__ob__', this)
if (Array.isArray(value)) {
// 这里对数组进行单独处理
if (hasProto) {
protoAugment(value, arrayMethods)
} else {
copyAugment(value, arrayMethods, arrayKeys)
}
this.observeArray(value)
} else {
// 对对象遍历所有键值
this.walk(value)
}
}
walk (obj: Object) {
const keys = Object.keys(obj)
for (let i = 0; i < keys.length; i++) {
defineReactive(obj, keys[i])
}
}
observeArray (items: Array<any>) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i])
}
}
}对于对象是通过Object.keys()遍历全部的键值,对数组只是observe监听已有的元素,所以通过下标更改不会触发响应式更新。
理由是数组的键相较对象多很多,当数组数据大的时候性能会很拉胯。所以不开放
computed 和 watch
Computed 的大体实现和普通的响应式数据是一致的,不过加了延时计算和缓存的功能:
在访问computed对象的时候,会触发 getter ,初始化的时候将 computed 属性创建的 watcher (vue3是副作用渲染函数)添加到与之相关的响应式数据的依赖收集器中(dep),然后根据里面一个叫 dirty 的属性判断是否要收集依赖,不需要的话直接返回上一次的计算结果,需要的话就执行更新重新渲染视图。
watchEffect?
watchEffect会自动收集回调函数中响应式变量的依赖。并在首次自动执行
推荐在大部分时候用 watch 显式的指定依赖以避免不必要的重复触发,也避免在后续代码修改或重构时不小心引入新的依赖。watchEffect 适用于一些逻辑相对简单,依赖源和逻辑强相关的场景(或者懒惰的场景 )
$nextTick 原理?
vue有个机制,更新 DOM 是异步执行的,当数据变化会产生一个异步更行队列,要等异步队列结束后才会统一进行更新视图,所以改了数据之后立即去拿 dom 还没有更新就会拿不到最新数据。所以提供了一个 nextTick 函数,它的回调函数会在DOM 更新后立即执行。
nextTick 本质上是个异步任务,由于事件循环机制,异步任务的回调总是在同步任务执行完成后才得到执行。所以源码实现就是根据环境创建异步函数比如 Promise.then(浏览器不支持promise就会用MutationObserver,浏览器不支持MutationObserver就会用setTimeout),然后调用异步函数执行回调队列。
所以项目中不使用$nextTick的话也可以直接使用Promise.then或者SetTimeout实现相同的效果
Vue 异常处理
1、全局错误处理:Vue.config.errorHandler
Vue.config.errorHandler = function(err, vm, info) {};
如果在组件渲染时出现运行错误,错误将会被传递至全局Vue.config.errorHandler 配置函数 (如果已设置)。
比如前端监控领域的 sentry,就是利用这个钩子函数进行的 vue 相关异常捕捉处理
2、全局警告处理:Vue.config.warnHandler
Vue.config.warnHandler = function(msg, vm, trace) {};注意:仅在开发环境生效
像在模板中引用一个没有定义的变量,它就会有warning
3、单个vue 实例错误处理:renderError
const app = new Vue({
el: "#app",
renderError(h, err) {
return h("pre", { style: { color: "red" } }, err.stack);
}
});和组件相关,只适用于开发环境,这个用处不是很大,不如直接看控制台
4、子孙组件错误处理:errorCaptured
Vue.component("cat", {
template: `<div><slot></slot></div>`,
props: { name: { type: string } },
errorCaptured(err, vm, info) {
console.log(`cat EC: ${err.toString()}\ninfo: ${info}`);
return false;
}
});注:只能在组件内部使用,用于捕获子孙组件的错误,一般可以用于组件开发过程中的错误处理
5、终极错误捕捉:window.onerror
window.onerror = function(message, source, line, column, error) {};它是一个全局的异常处理函数,可以抓取所有的 JavaScript 异常
Vuex 流程 & 原理
Vuex 利用 vue 的mixin 机制,在beforeCreate 钩子前混入了 vuexinit 方法,这个方法实现了将 store 注入 vue 实例当中,并注册了 store 的引用属性 store.xxx`去引入vuex中定义的内容。
然后 state 是利用 vue 的 data,通过new Vue({data: {$$state: state}} 将 state 转换成响应式对象,然后使用 computed 函数实时计算 getter
Vue.use函数里面具体做了哪些事
概念
可以通过全局方法Vue.use()注册插件,并能阻止多次注册相同插件,它需要在new Vue之前使用。
该方法第一个参数必须是Object或Function类型的参数。如果是Object那么该Object需要定义一个install方法;如果是Function那么这个函数就被当做install方法。
Vue.use()执行就是执行install方法,其他传参会作为install方法的参数执行。
所以**Vue.use()本质就是执行需要注入插件的install方法**。
源码实现
export function initUse (Vue: GlobalAPI) {
Vue.use = function (plugin: Function | Object) {
const installedPlugins = (this._installedPlugins || (this._installedPlugins = []))
// 避免重复注册
if (installedPlugins.indexOf(plugin) > -1) {
return this
}
// 获取传入的第一个参数
const args = toArray(arguments, 1)
args.unshift(this)
if (typeof plugin.install === 'function') {
// 如果传入对象中的install属性是个函数则直接执行
plugin.install.apply(plugin, args)
} else if (typeof plugin === 'function') {
// 如果传入的是函数,则直接(作为install方法)执行
plugin.apply(null, args)
}
// 将已经注册的插件推入全局installedPlugins中
installedPlugins.push(plugin)
return this
}
}使用方式
installedPlugins im



